最近在写一个宏(用来检查Define.xml中CRF页码是否与aCRF上的页码一致)的时候有用到单词边界(“\b”)这个定位符,在SAS在线文档中有其说明:\b matches a word boundary (the position between a word and a space),即“\b”匹配的是单词与空格之间的位置,这种表述其实是不准确的,文档的作者已经确认下一版会更新,详见这里。比如“\b”匹配“_”与“*”之间的位置,而不匹配“_”与“_”之间的位置,所以正确的表述应该是“\b”匹配的是单词字符(\w)和非单词字符(\W)之间的位置。单词字符包括字母数字字符和下划线[a-zA-Z0-9_];非单词字符包括不为字母数字字符或下划线的任何字符。“\b”匹配单词边界,不匹配任何字符,是零宽度的;匹配的只是一个位置,这个位置的一侧是构成单词的字符,另一侧为非单词字符、字符串的开始或结束位置。“\b”一般应用需要匹配某一单词字符组成的字符串,但这一字符不能包含在同样由单词字符组成的更长的字符中。下面通过一个实例来简单的介绍一下这个元字符。
设有宏变量varlst的值为”LBCAT|LBSTAT|LBTEST|LBTESTCD“,字符串VAR_HAVE="LBSTAT=NOT DONE when LBTESTCD=LBALL and LBCAT=HEMATOLOGY",想要实现的是将字符串VAR_HAVE中非宏变量中的单词删除掉,即只保留宏变量中出现的单词。分情况讨论:
- 当程序为:
%let varlst=LBCAT|LBSTAT|LBTEST|LBTESTCD; data test; VAR_HAVE='LBSTAT=NOT DONE when LBTESTCD=LBALL and LBCAT=HEMATOLOGY'; VAR_WANT=compbl(prxchange("s/.*?(&varLst.)?/$1 /", -1, cats(VAR_HAVE))); PUT VAR_WANT=; run;VAR_WANT="LBSTAT LBTEST LBCAT",解释:因为SAS中正则表达式引擎为非确定性有穷自动机(NFA: Non-Deterministic Finite Automaton),表达式从左往右匹配,当匹配到“LBTEST”时因为没有使用“\b”即成功,不再尝试后面那个子正则式"/LBTESTCD/",接着往下继续匹配。
- 当程序为:
%let varlst=LBCAT|LBSTAT|LBTEST|LBTESTCD; data test; VAR_HAVE='LBSTAT=NOT DONE when LBTESTCD=LBALL and LBCAT=HEMATOLOGY'; VAR_WANT=compbl(prxchange("s/.*?(\b&varLst.\b)?/$1 /", -1, cats(VAR_HAVE))); PUT VAR_WANT=; run;VAR_WANT="LBSTAT LBTEST LBCAT",解释:虽然用了“\b”,宏变量解析后表达式中的括号内为: "\bLBCAT|LBSTAT|LBTEST|LBTESTCD\b",因为是NFA,当匹配到“LBTEST”时即成功,不再尝试后面那个子正则式"/LBTESTCD\b/",接着往下继续匹配。所以为了精确匹配"LBTESTCD",需要在每个单词后面加上“\b”,即下面的程序:
- 当程序为:
%let varlst=LBCAT|LBSTAT|LBTEST|LBTESTCD; data test; VAR_HAVE='LBSTAT=NOT DONE when LBTESTCD=LBALL and LBCAT=HEMATOLOGY'; VAR_WANT=compbl(prxchange("s/.*?(\b(&varLst.)\b)?/$1 /", -1, cats(VAR_HAVE))); PUT VAR_WANT=; run;VAR_WANT="LBSTAT LBTESTCD LBCAT",解释:宏变量解析后表达式中的括号内等同于: "\bLBCAT\b|\bLBSTAT\b|\bLBTEST\b|\bLBTESTCD\b",但是表达式是从左往右匹配,当匹配到“LBTEST”时不成功,因为后面有字母"CD",故与"\bLBTEST\b"不匹配,接着往后继续匹配。当匹配到“LBTESTCD”时成功,因为后面的等号"=",满足单词边界的要求,故与"\bLBTESTCD\b"匹配。当然,为了提高效率可以加上非捕获匹配符(?:),表达式如下:
pattern="/.*?(\b(?:&varLst.)\b)?/";
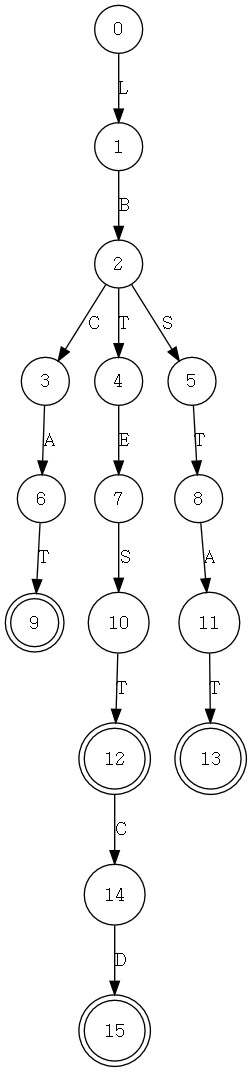
说到正则表达式引擎,还有一种称为确定性有穷自动机(DFA: Deterministic Finite Automaton)。NFA与DFA最大的区别在于:NFA是最左子正则式优先匹配成功,因此偶尔可能会错过最佳匹配结果;DFA则是最长的左子正则式优先匹配成功。最后推荐一个可视化正则表达式NFA/DFA的小神器。上面表达式的可视化结果如下:
1.NFA

2. DFA