SAS程序猿/媛都知道SAS有滞后函数LAG。那我们会问有没有与之相反的领先函数呢?答案是否定的。但是,我们有其他的替代方法。最简单的方法就是新建一个值为_N_的排序变量,然后逆向排序,使用LAG函数,再正向排序。方法虽然简单明了,但是要多个PROC+DATA步,而且数据较大时,效率会很低。下面介绍其他两种方法:
- 双SET:
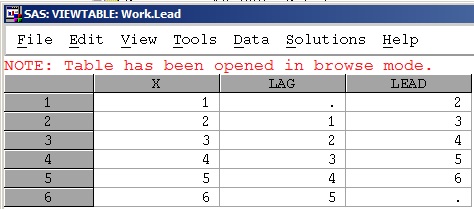
data demo; input X @@; cards; 1 2 3 4 5 6 ; run; data lead; set demo end=eod; LAG=lag(X); if not eod then do; VAR_TEMP=_N_+1; set demo(keep=X rename=X=LEAD) point=VAR_TEMP; end; else LEAD=.; keep X LAG LEAD; run; - HASH:
data lead; retain X; if _N_=1 then do; dcl hash h(ordered: 'a') ; h.definekey('LEAD_SEQ'); h.definedata('LEAD_SEQ', 'LEAD'); h.definedone(); dcl hiter hi('h'); do until(eof); set demo(rename=X=LEAD) end=eof; LEAD_SEQ+1; h.add(); end; end; set demo; LAG=lag(X); hi.setcur(key: _N_); /*Specifies a starting key item for iteration*/ rc=hi.next(); if rc^=0 then LEAD=.; drop LEAD_SEQ RC; run;
上面第一种方法程序行数虽然少,但是有两次SET的操作,所以当数据集较大时建议采用第二种方法以提高效率。