In SDTM domains, all character variables are limited to a maximum of 200 characters due to FDA requiring datasets in SAS v5 transport format. Text more than 200 characters long should be stored as a record in the SUPP–dataset. To improve readability the text should be split between words not just broken the text into 200-character. In this post, I’ll introduce a method using regular expression. Syntax: PRXCHANGE (regular-expression-id|perl-regular-expression, times, source). Example:
VAR=prxchange('s/(.{1,200})([\s]|$)/\1~/', -1, cats(VAR));Regular expression visualization by Regexper:
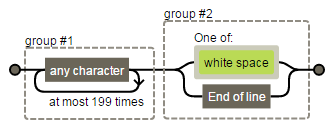
Here’s a brief explanation. Expression looks at character 201 – if it’s a space, the split character is inserting. Otherwise, it locates the position of the rightmost breaking character and inserts a split character. The process is repeated on the remaining characters in the string until the end of the variable VAR. And finally we can use SCAN function to extract individual words from the variable based on the delimiter (~), and each chunk is assigned to a new variable.